Agent Leaderboard
Last updated:
Model | Score | Cost ($) | Est. Runtime (s) |
|---|---|---|---|
Loading radar chart...
Shown are scores averaged over first across all instances per task category (Radar chart to the right). Averaged scores per task are then aggregated across all tasks to get the overall score (table to the left). Runtime is estimated as (number of ReAct steps + 1) × average time per step for a given model, rather than wall-clock time, which is affected by our internal queue depths, provider TPM limits, deployments, and other operational factors.
Best Accuracy per Dollar on DRB
No data available
Best Accuracy per Second on DRB
No data available
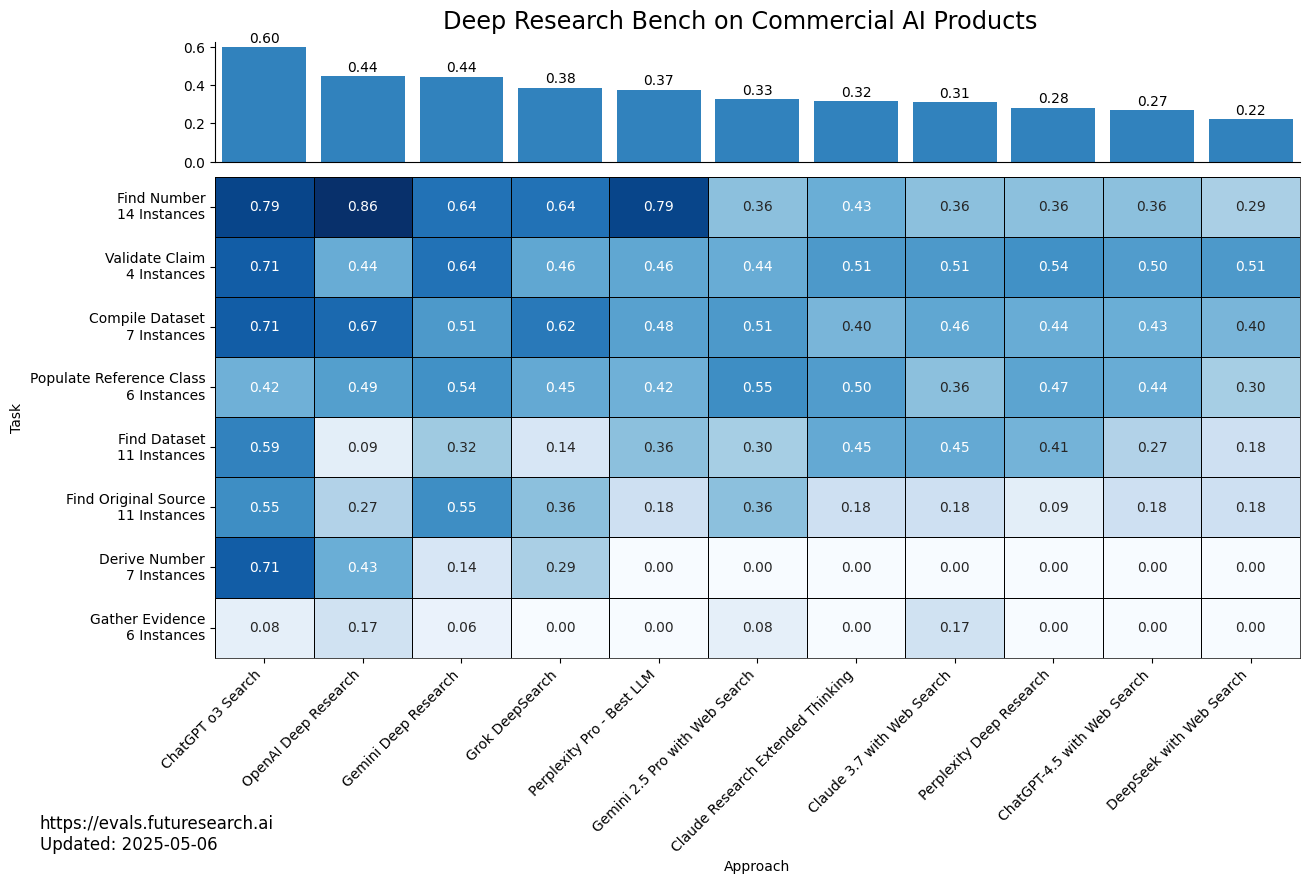
Commercial AI products
The following heatmap shows the performance of commercial AI products on Deep Research Bench.